As part of my learning journey outside of regular work, I challenged myself to build a small but meaningful project within a limited timeframe. Instead of focusing on something big, I wanted to create a tool that encourages curiosity, exploration and makes my work productive. That’s how Skill Searcher came to life—a simple web app built to explore skills easily and intuitively, while I was taking note of all the things that could work properly, so that I can easily go through all the skills that I want to study without going to different places or platforms and getting confused.
Live Project: https://skills-selector-db.netlify.app/
What I was trying to do
I wanted to build a lightweight skill discovery tool that helps users explore different skills without noise or complexity.
The idea was simple:
I wanted something I personally could use when thinking about what to learn next — beyond just career requirements.
What I built or set up
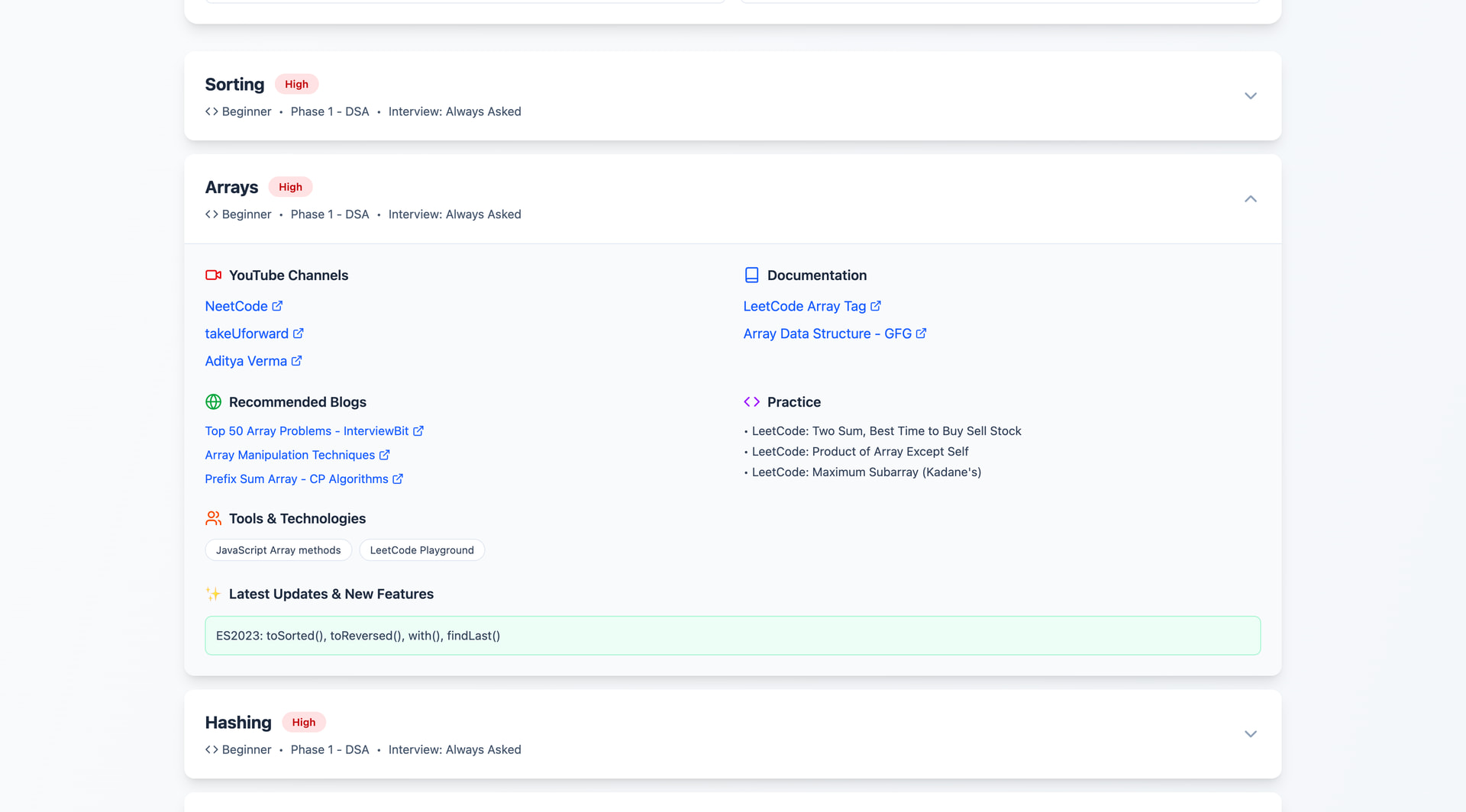
I built Skill Searcher, a frontend web application that allows users to:
-
Search skills dynamically
-
Filter results in real time
-
Instantly view relevant skills
-
Use a clean and distraction-free interface
Technical setup included:
-
React for component structure and state management
-
API-based data fetching for skills
-
Client-side filtering logic
-
Deployment on Netlify for quick public access
The focus was not just on functionality but on a smooth user experience.
What did not go well at the start (and how I fixed it)
This project did not work smoothly at first—it took 5–6 iterations to get things right.
Filtering logic issues
Initially, filtering didn’t work as expected:
-
Empty results were returned
-
Case sensitivity broke the matching:
-
Filters ran before API data was fully available
How I overcame it:
I normalised both user input and API data, ensured state updates were completed before filtering, and restructured the logic to run only after data was loaded. To make the filtering work successfully to deal with the casing of characters, I followed the code:
const filteredSkills = SkillsData.filter(skill => {
const matchesSearch = skill.name.toLowerCase().includes(searchTerm.toLowerCase()) ||
skill.category.toLowerCase().includes(searchTerm.toLowerCase());
const matchesCategory = selectedCategory === 'All' || skill.category === selectedCategory;
return matchesSearch && matchesCategory;
});
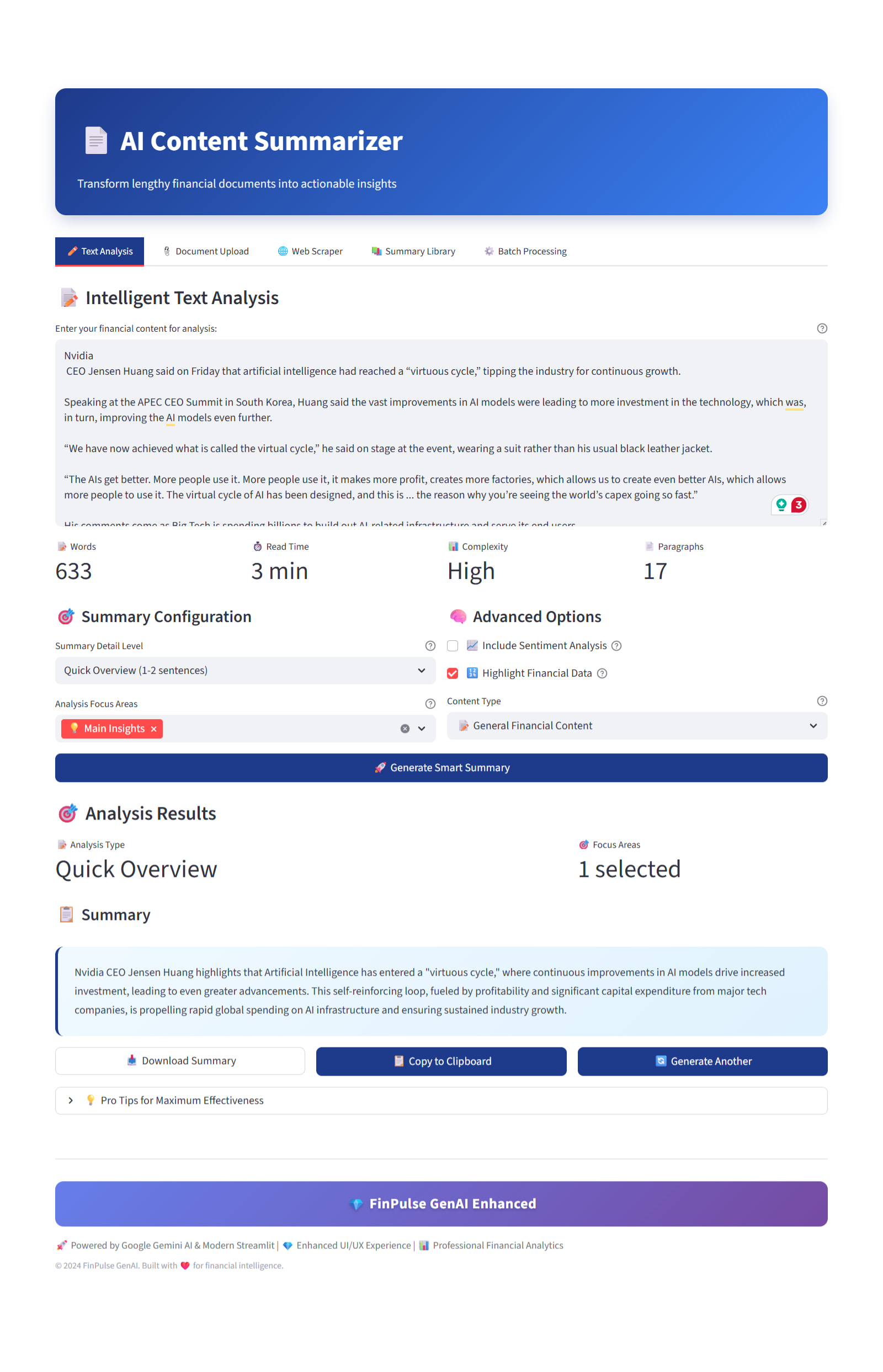
API fetching and response handling problems
While I was testing out the API over Postman, I got many issues, and I struggled with:
-
404 Not Found Due to incorrect endpoints
-
500 Internal Server Error from malformed requests
-
undefined data caused by incorrect response assumptions
Even when the API responded, nothing rendered on the UI.
How I overcame it:
I logged the raw responses, carefully studied the JSON structure, and rebuilt the response mapping instead of guessing. I also added defensive checks to avoid UI crashes.
Multiple rebuild attempts
I had to refactor:
-
Data flow
-
Rendering logic
-
Filtering conditions
Several times before, everything worked together smoothly. Each failed attempt improved my understanding of state, async behaviour, and data reliability.
Why it mattered to me
This project really solved my problem, as all the resources to study for each type of skill were present in the same place, such as blogs and YouTube channels, while I was preparing for my interviews. This project also reminded me that real learning happens when things break.
Skill Searcher helped me:
-
Improve debugging skills
-
Better understand API responses
-
Learn patience and persistence
-
Build something useful outside of work pressure
Although I know there could be many improvements I could make, such as a fallback template or code and good interactivity, more than the final product, the journey—failing, fixing, and finally making it work—is what made this project valuable to me, and it helped to make my work productive and easy.